ControlNet-XS: Rethinking the Control of Text-to-Image Diffusion Models as Feedback-Control Systems
ECCV 2024 (Oral)


With increasing computing capabilities, current model architectures appear to follow the trend of simply upscaling all components without validating the necessity for doing so. In this project, we investigate the size and architectural design of ControlNet [Zhang et al., 2023] for controlling the image generation process with stable diffusion-based models. We show that a new architecture with as little as 1% of the parameters of the base model achieves state-of-the art results and performs considerably better than ControlNet in terms of FID score. Hence, we call it ControlNet-XS. We provide the code for controlling StableDiffusion-XL [Podell et al., 2023] (Model B, 48M Parameters) and StableDiffusion 1.5 [Rombach et al. 2022] (Model B, 14M Parameters) and StableDiffusion 2.1 (Model B, 14M Parameters), all under openrail license. The different models are explained in the Method section below.
We evaluate differently sized control models and confirm that the size does not even have to be of the same magnitude as the base U-Net network, which has 2.6B paramaters. The control is evident for sizes of ControlNet-XS of 400M, 104M and 48M parameters, as shown below for guidance with depth maps (MiDaS [Ranftl et al., 2020]) and Canny edges, respectively. A row shows three example results of Model B, each with a different seed. Note, we use the same seed for each column.


We show generations of three versions of ControlNet-XS with 491M, 55M and 14M parameters respectively. We control Stable Diffusion with depth maps (MiDaS) and Canny edges. Even the smallest model with 1.6% of the base model size, which has 865M parameters, is able to reliably guide the generation process. As above, a row shows three example results of Model B, each with a different seed. Note, we use the same seed for each column.


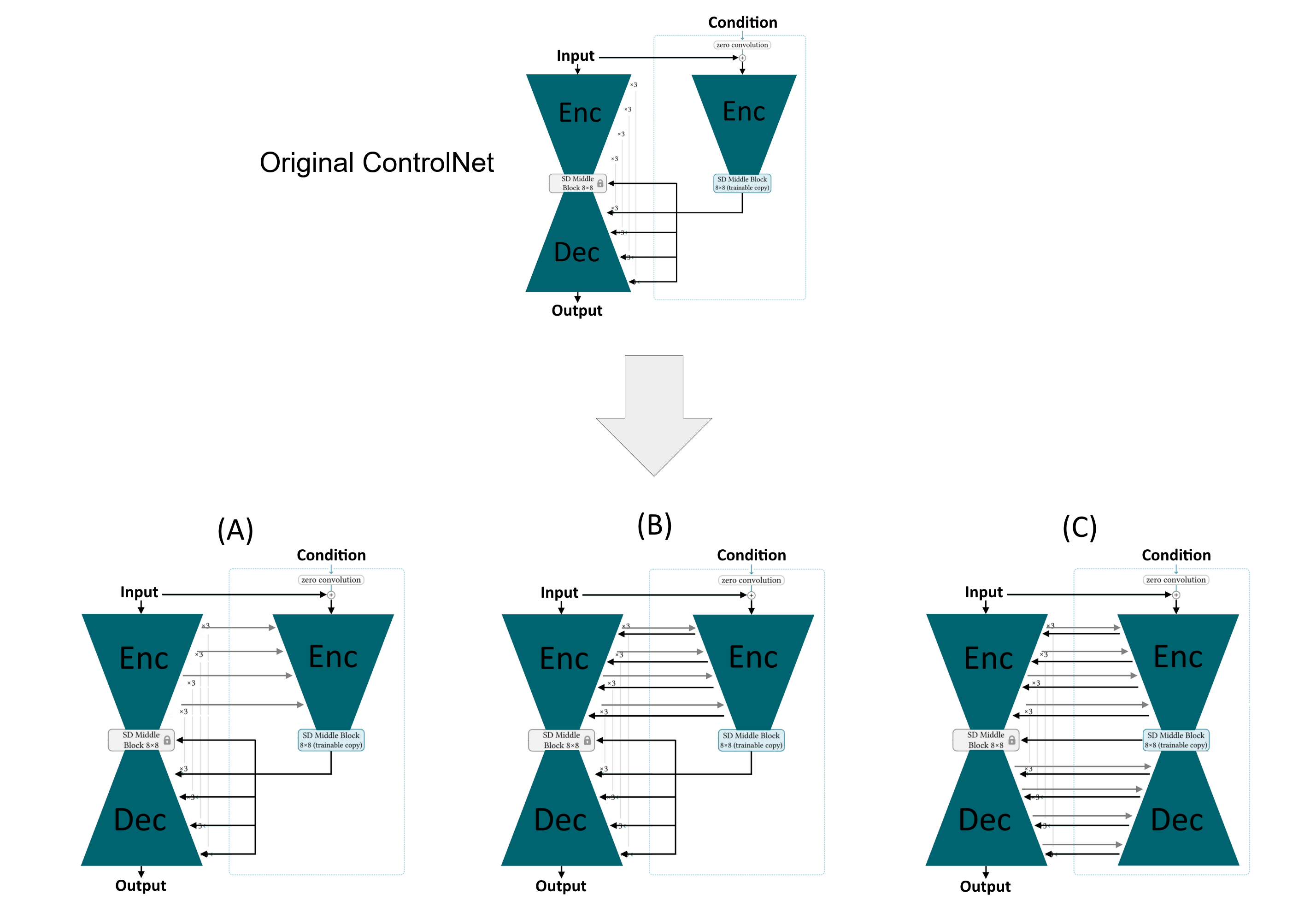
The original ControlNet is a copy of the U-Net encoder in the StableDiffusion base model, and hence receives the same input as the base model with an additional guidance signal like an edge map. The intermediate outputs of the trained ControlNet are then added to the inputs of the decoder layers of the base model. Throughout the training process of ControlNet, the weights of the base model are kept frozen. We identify several conceptual issues with such an approach leading to an unnecessarily large ControlNet and to a significant reduction in quality of the generated image:
We address the first problem (i) of delayed feedback by adding connections from the Encoder base model into the controlling Encoder (A). In this way, the corrections can adapt more quickly to the generation process of the based model. Nonetheless, it does not eliminate the delay entirely, since the encoder of the base model still remains unguided. Hence, we add additional connections from ControlNet-XS into the base model encoder, directly influencing the entire generative process (B). For completeness, we evaluate if there is any benefit in using a mirrored, decoding architecture in the ControlNet setup (C).
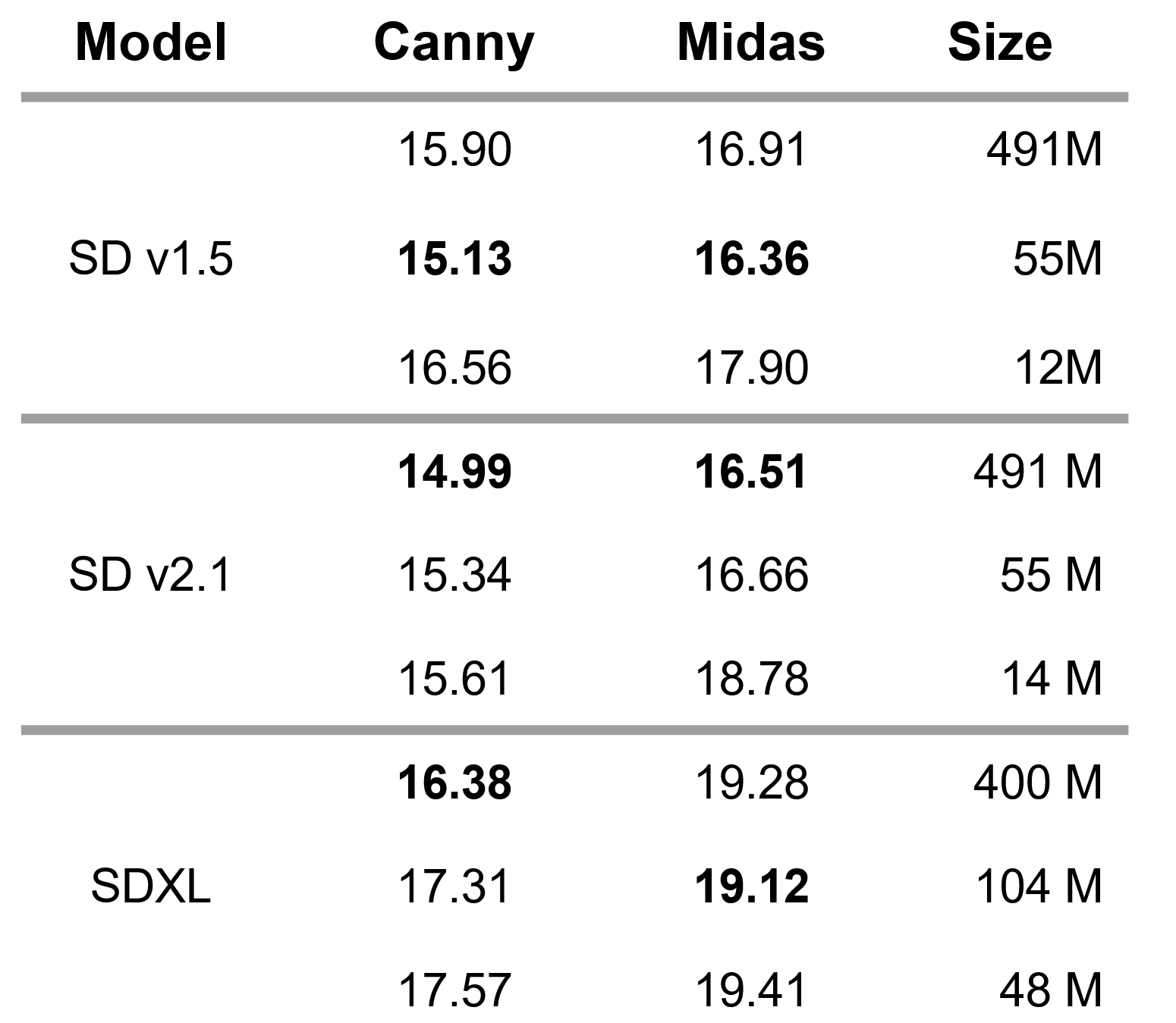
We evaluate the performance of three variations (A, B, C) for Canny edge guidance in comparison to the original ControlNet in terms of FID-score over the validation set of COCO2017 [Lin et al., 2014]. All of our variations achieve a significant improvement, while having just a fraction of the parameters of the original ControlNet.

We focus our attention on variant B and train it with different model sizes for canny and depth map guidance, respectively, for StableDiffusion 1.5, StableDiffusion 2.1 and the current StableDIffusion-XL version.
@inproceedings{zavadski2024controlnet,
title={ControlNet-XS: Rethinking the Control of Text-to-Image Diffusion Models as Feedback-Control Systems},
author={Zavadski, Denis and Feiden, Johann-Friedrich and Rother, Carsten},
booktitle={European Conference on Computer Vision},
pages={343--362},
year={2024},
}